使用 datashader 與 mercantile 建立 OpenStreetMap 圖磚系統 (version 2)
在上一篇文章中已展示過了已展示如何從 NYC taxi trip dataset 中建立 map tiles 的基本方式。本篇將進一步改進該演算法,加速產生速度以及大檔案方式。
Concept
和前篇的 map tiles 建立方式方式相比,新方法著重在
- Concurrency (平行化)
- 盡可能將處理單元拆成獨立部分,並使用 concurrent.futures 套件將任務平行處理,讓多 CPU 能充分發揮處理能力。
- 單一大檔案處理
- 以 Divide and Conquer 概念來分割檔案,轉換為適合的處理格式再平行處理。
- 加速 Map Tiles 建立
- 對每個處理單元中點數所屬的 Map tile 進行 Group 後再進行 Aggregate。
- Bottom-Up 建立 Map Tile
- 從基底 Tiles 以由下往上 (Bottom-Up) 合併的方式建立新 Map Tile。
- 修改繪圖方式
- 分別使用 Histogram_Equalization 與 Log 方式(需紀錄每個 zoom 中 pixel 最大點為)來繪製 Map tile 來取得較好的繪圖效果。
下方將展示演算法概念,詳細程式碼可參考 Github 上的 ipython notebook。
資料前處理
Download NYC Taxi Trip Data
使用 wget 指令取得 NYC Taxi trip data,這裡一樣使用 2016 年 5 月的計程車資料。
wget https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_2016-05.csv
將原始 CSV 分割為小檔案
依照資料筆數切割為許多小檔案
mkdir split # 建立 split 資料夾
# 以 1,000,000 lines 為單位,將原始 csv 檔案分割為數個檔案(不包含 header)
tail -n +2 yellow_tripdata_2016-05.csv | split -d -l 1000000 - split/trip.csv.
完成後可得到 split/trip.csv.00,split/trip.csv.01 等不包含標頭的分割檔
若使用 mac 可先安裝 coreutils,並將
tail與split指令換成gtail與gsplit並執行即可。
轉換 csv 內容到目標格式
將 csv 檔案轉換到包含 Web Mercator 格式座標(epsg:3857)以及所在基底 Tile 的座標資料。
with futures.ProcessPoolExecutor() as executor:
datas = zip(source_csvs, epsg3857_csvs, [base_zoom] * len(source_csvs))
fs = executor.map(convTripGpsToWebMercatorWrapper, datas)
futures.as_completed(fs)
轉換完成後可得到如下方格式的 csv 檔案
| x | y | zoom | xtile | ytile |
|---|---|---|---|---|
| Web Mercator X | Web Mercator - Y | 地圖基底 zoom | Map Tile X 位置 | Map Tile Y 位置 |
建立 map tile aggregation file
建立基底 zoom 中,有包含點位資料的 aggregation files
- 用 Pandas 讀取分割的 csv 檔案。
- 使用 Groupby 計算所需建立的 tile group,避免沒必要的 aggregate 計算。
- 使用 Group 後的座標資料建立 aggregation data
- 使用 concurrent.futures 進行平行處理,加快計算速度。
def makeTilesAggregation(source, root):
if not os.path.exists(source):
raise ValueError(f'Source file {source} doesn\'t exist')
os.makedirs(root, exist_ok=True)
df = pd.read_csv(source,
usecols=['x', 'y', 'zoom', 'xtile', 'ytile'],
dtype={'x':np.float32,
'y':np.float32,
'zoom':np.int8,
'xtile':np.int32,
'ytile':np.int32})
for ((zoom, xtile, ytile), data) in df.groupby(by=['zoom', 'xtile', 'ytile']):
agg = mapTileCanvas(xtile, ytile, zoom).points(data, 'x', 'y')
serializeAggToFile(agg, getAggFilePath(root, xtile, ytile, zoom))
serializeAggYaml(agg, getAggYamlFilePath(root, xtile, ytile, zoom))
def makeTilesAggregationWrapper(data):
source, root = data
makeTilesAggregation(source, root)
- 平行化建立 Map tiles
with futures.ProcessPoolExecutor() as executor:
targets_root = [os.path.join(temp_root, os.path.basename(f)) for f in epsg3857_csvs]
datas = zip(epsg3857_csvs, targets_root)
fs = executor.map(makeTilesAggregationWrapper, datas)
futures.as_completed(fs)
合併 aggregation files
合併所有 map tiles aggregation files,成為一個包含所有分割 csv 資料的整合 aggregation,並將其當作是基底 map tile 資料。
# 平行化合併處理方式
with futures.ProcessPoolExecutor() as executor:
tiles = getCombineTiles(glob.glob(os.path.join(temp_root, '*')))
tiles_chunk = list(chunks(tiles, chunksSize(len(tiles), 4)))
tiles_tuple = zip(tiles_chunk, [temp_root] * len(tiles_chunk), [agg_root] * len(tiles_chunk))
fs = executor.map(combineAggregationWrapper, tiles_tuple)
futures.as_completed(fs)
使用 Bottom-Up 方式合併並產生上層 zoom 的 map tiles
-
從基底 tile 的 aggregation 的檔案中建立所有 parents tile 列表。
-
讀取 parents tile 中所有的 child tiles 檔案並合併資料後,再寫入 parents tile(如果有的 child tiles 不存在,則建立內部為空值的 map tile)
-
假如 tile 座標為 (xtile, ytile, zoom) = (23, 43, 6),則該 tile 的 parenet 為 ptile = (11, 21, 5)。
-
而 pTile 的 四個 children tiles 分別為 (22, 42, 6), (23, 42, 6), (23, 43, 6), (22, 43, 6)。
-
因此 pTile 的 aggregation file 可從四個 children tiles 中合併得來
-
-
不斷往上建立 parents tiles 直到 zoom 0 為止。
for zoom in range(base_zoom, 0, -1):
print(f'Make parents tiles from zoom {zoom}')
with futures.ProcessPoolExecutor() as executor:
tiles = [(agg_root, x, y, z) for x, y, z in getParentTiles(agg_root, zoom)]
tiles_chunk = chunks(tiles, chunksSize(len(tiles), 4))
fs = executor.map(makeTilesBottomUpWrapper, tiles_chunk)
futures.as_completed(fs)
建立每個 zoom 中的最大點數資料
掃描 zoom 中每個 tile 的最大點位資料,並儲存進 {zoom}/zoom_config.yaml 中(與前篇方式相同)。
# 計算 zoom 中的最大點數資料
def getZoomMaxCount(zoom_root):
max_count = 0;
for root, dirs, files in os.walk(zoom_root):
for file in files:
exts = file.split(os.extsep)
if os.path.splitext(file)[1] != '.yaml':
continue
mc = getYamlMaxCount(os.path.join(root, file))
max_count = mc if max_count < mc else max_count
return max_count
for zoom in os.listdir(agg_root):
max_count = getZoomMaxCount(os.path.join(agg_root, zoom))
zoom_yaml = os.path.join(agg_root, zoom, 'zoom_config.yaml')
with open(zoom_yaml, 'w') as file:
yaml_obj = {'max_count': max_count}
yaml.dump(yaml_obj, file, default_flow_style=False)
產生 Aggregation 檔案對應的 Tile 影像
- 建立所有要繪製圖片的 aggregation 列表,並設定繪製方式。
- 如果使用 Log 方法繪製,則先讀取之前建立好的 zoom max count 值為數值範圍。
- 建立對應的 PNG 影像圖磚。
 位置為 /11/603/769.png 的 map tile(背景為透明)
位置為 /11/603/769.png 的 map tile(背景為透明)
使用 Folium 顯示 map tile
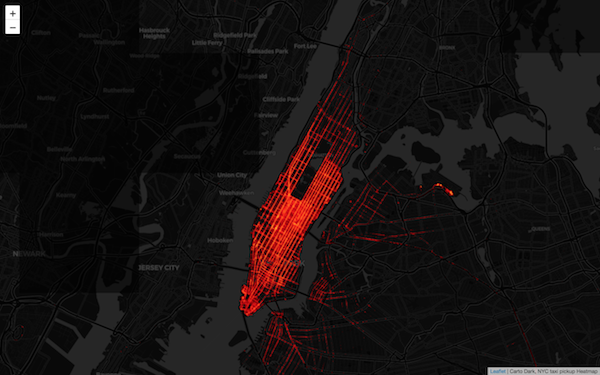
Conclusion
本篇文章在現有基礎上加強了建立圖磚演算法的效率,並且可經由平行化的方式快速繪製 map tiles。詳細程式碼可參考 Github 上的 ipython notebook
