高效卷積計算結構 - Depthwise Separable Convolution
近年來因與計算機的計算能力大幅上升,GPGPU 的支援等,使深度神經網路技術取得了非常好的效果發展。但所衍生的高計算量卻讓行動裝置以及嵌入式系統等計算能力有限的平台在執行時遇到效能的限制。因此 Google 在 MobileNets 模型中使用了新的卷積計算模型 depthwise separable convolution 來減少所需的計量。本篇將從基礎類神經網路開始介紹,說明卷積神經網路的架構與計算成本問題,並解說 depthwise separable convolution 的技術內容與計算成本。
MobileNets
自從 Google 在 2015 釋出 TensorFlow 機器學習工具後,使 Machine Learning 包含 Deep Learning 等研究與實作更為方便。但 TensorFlow 程式庫需要大量的資源與空間,如要在嵌入式系統上有許多的限制。因此之後 Google 接續提出了 TensorFlow Mobile 以及 TensorFlow Lite 等來減少執行所需的資源花費。
此外經由 TensorFlow 深度學習模型所需的儲存空間非常大,如其中 Inception v3 模型本身約有 91 MB,內部包含 2500 萬個參數與 50 億次乘法加法運算,因此也可以透過 Freeze Graph 以及 Quantization 的步驟來縮小模型。
雖然可以透過上面所提的技減少執行空間,但執行深度學習模型所需的運算量仍然非常巨大,因此 Google 也在 2017 年提出了 MobileNets 模型並使用 depthwise separable convolution 技術,從根本上減少在原先的 convolutional neural network (CNN) 中所需要的巨大運算複雜度。以下會從基本的 artificial neural network (NN) 談起,再介紹 CNN 網路架構與問題,最後說明 MobileNets 中的 depthwise separable convolution 架構。
Artificial neural network
Artificial neural network (或稱 Multi-layer perceptrons) 是一個經典的機器學習模型,主要的概念來自於人類大腦的神經元結構。標準的 neural network 主要包含下面三部分 - input layer (輸入層),hidden layer (隱藏層) 以及 output layer (輸出層),每一層都有不同的任務與功能。
Input layer
原始資料的輸入來源,將資料導入 hidden layer。以一張長寬為 (10, 10) 的圖片為例,input layer 即為 10 * 10 = 100 個像素的值。
Hidden layer
Hidden layer 中的每個 neuron 會接收上一層的輸入資料,經過乘以權重並加總後,透過 activation function 將資料輸出。假設一個 neuron 的上一層有 $i$ 個輸出,則該 neuron 的輸出可計算為
$$output = \sigma(\sum\limits_{i}w_{i}x_{i} + b)$$其中
$$x_i$$為第
$$i$$個輸出,
$$w_i$$為對第
$$i$$個輸出值 neuron 的 weight (權重),
$$b$$為 bias 值,
$$\sigma$$為所設定的 activation function 如 Sigmoid,ReLu 等的函數。
Output layer
在經過所有 hidden layers 計算後得到的輸出結果,在不同的問題有不同表述,如在圖像分類時 output layer 的每個 neuron 可代表不同類別的評分,我們可以取最高值的 neuron 所代表的類別當作輸入圖像的類別。
下圖為 NN 模型的簡單結構圖,其中 input layer 包含 3 個 neuron,output layer 則包含 1 個 neuron。而 hidden layer 有兩層,且每層有 4 個 neuron。
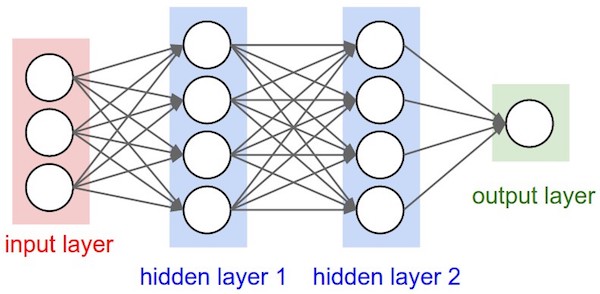 Structure of artificial neural network (From: Stanford cs231n)
Structure of artificial neural network (From: Stanford cs231n)
Training
那要如何讓模型具有學習能力,讓 NN 模型能自動調整所有的 weight
$$w$$,得出想要的結果? 我們可以透過 loss function 與 backpropagation (反向傳播) 演算法,讓模型去自動調整模型中的 weight 讓誤差越來越小。主要步驟為
- 定義模型的 loss function 來代表模型計算結果與真正結果之間的差異量。
- 將資料集中的資料放入模型中,經過運算可得到 loss function 的值,再透過 backpropagation 演算法不斷的調整每個 weight 的值,讓得出的 loss function 值越來越小。
- 不斷的重複第二步驟直到達到停止條件為止。
更詳細的說明可參考 Standard cs231n 課程中的介紹。
Convolutional neural network
除了傳統的 NN 外,還有另一種被稱為 Convolutional neural network (CNN) 的神經網路演算法,此方法考慮到空間結構並使用了多個 kernel (filter) 來對樣本空間進行計算,在影像辨識與自然語言處理等領域均已經取得了重大成效。如在圍棋領域戰勝世界冠軍的 AlphaGo,其背後演算法也採用了 CNN 架構來進行推論。
與前面提到的標準 NN 不同,CNN 運用多個 kernel 對輸入層進行 convolution (卷積) 計算後並透過 activation function 將輸入層的資料轉換到輸出層,計算得到的輸出層也可當做下一次 convolution 的輸入層,透過此方式最終將資料導向 output layer,如下圖所示
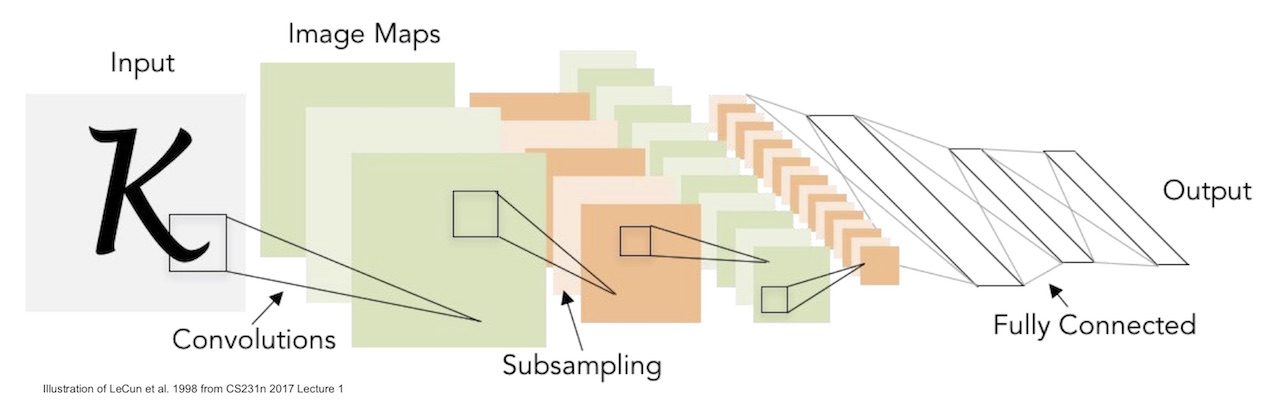 Structure of convolutional neural network (From: Stanford cs231n)
Structure of convolutional neural network (From: Stanford cs231n)
雖然 convolutional Neural Network 功能強大但計算成本也相當高。假設現在對輸入層 feature map
$$F$$透過 kernel
$$K$$進行 convolution 運算後得到輸出層 feature map
$$G$$,其中
- $$D_F$$:Feature map $$F$$ 的長寬。
- $$M$$:Feature map $$F$$ 的 channel 數量。
- $$D_K$$:Kernel $$K$$ 的長寬。
- $$N$$:Feature map $$G$$ 的 channel 數量。
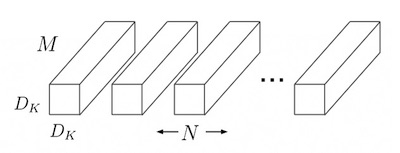 Filter of convolutional neural network
Filter of convolutional neural network
該次 convolution 運算的計算量為
$$D_K \cdot D_k \cdot M \cdot N \cdot D_F \cdot D_F$$channel 可想像影像中每個 pixel 的資料深度。例如灰階影像只需要一個維度來代表亮度則 channel 就為 1。而 RGB 影像需要三維資料來代表所以 channel 數為 3。
假設一個 224 x 224 的灰階影像(channel = 1),Kernel 長寬為 3 x 3 且輸出的 Feature Map 的 channel 數量為 10。則第一層總計算量約為 3 * 3 * 1 * 10 * 224 * 224 = 4,515,840,可看出光是單一層的卷積計算就需要非常大量的計算成本。在更大更深的深度卷積網路中將會是非常大的負擔。
 Structure of convolutional neural network
Structure of convolutional neural network
Depthwise separable convolution
為了減少 CNN 本身所需要的高度計算量問題,Google 在 MobileNet 中使用了一種對卷積神經網路的新計算結構 - depthwise separable convolution,以降低 CNN 模型所衍生的計算成本。該方式主要將原先的卷積計算方式拆成兩個部分 - depthwise convolutions 與 pointwise convolutions ,分別進行在不影響輸出結構的狀況下減少運算量。
Depthwise convolutions
通常 CNN 的 filter 深度會依照輸入層的 channel 大小深度變化,如寬高為 5 的 filter,假設輸入層 channel 數為 3,則 kernel 的維度大小為
$$5 \times 5 \times 3$$。而 depthwise convolution 層則是先對輸入層的每個 channel 建立一個
$$D_K \times D_K \times 1$$的 kernel
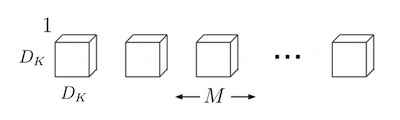 Depthwise convolutional filters
Depthwise convolutional filters
之後對該 channel 所有的資料進行 convolution 計算。假如輸入層有
$$M$$個 channel,則會建立
$$M$$個 kernel -
$$K_1$$,
$$K_2$$與
$$K_3$$,分別對三個 channel 的資料進行運算得出與輸出層相同寬高的中間層,之後將資料進行下一步的 pointwies convolutions。
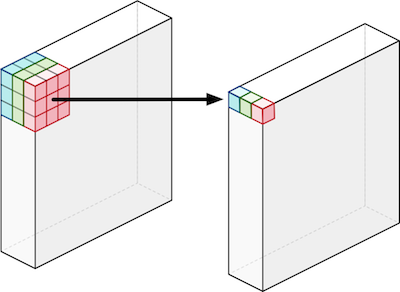 Structure of depthwise convolutions
Structure of depthwise convolutions
Pointwise convolutions
在每個 channel 進行過 depthwise Convolution 的步驟後,下一步是對每個點的所有 channel 值進行 pointwise convolutions。先對每個輸出 channel 建立一個大小為
$$1 \times 1 \times M$$的 Kernel 後 (
$$M$$為輸入層的 channel 數),將輸入層的所有點進行 convolution 運算。假如輸出層有
$$N$$個 channel,則會建立
$$N$$個
$$1 \times 1 \times M$$的 kernel
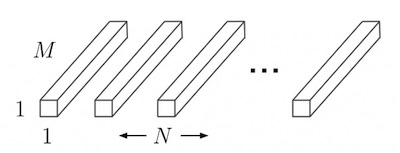 Pointwise convolutional filters
Pointwise convolutional filters
之後將每個 kernel 對輸入層進行運算後可得到大小為
$$D_G \times D_G \times N$$的輸出層(
$$D_G$$為輸出層的長寬)。該結果與原先 CNN 輸出層結構是相同的。
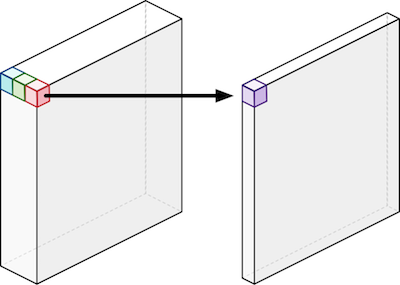 Structure of pointwise convolutions
Structure of pointwise convolutions
Comparision
下圖為標準 convolution 與 depthwise deparabel convolution 的流程比較。右方的 depthwise separable convolution 執行步驟看似比較多,但實際分析過後會發現實際計算量比使用傳統的 CNN 的模型減少相當多。
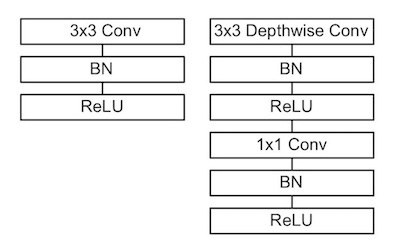 (Left) Standard convolution。 (Right) Depthwise separable convolution
(Left) Standard convolution。 (Right) Depthwise separable convolution
- Batch Normalization(BN):一種在 Neural Network 中用來進行參數正規化的技術。
- ReLU:時常在 NN 上使用的 Activition Function。
Performance
由前面的討論可知 depthwise convolutions 部分的計算量為
$$D_K \cdot D_K \cdot M \cdot D_F \cdot D_F$$而 pointwise convolutions 則為
$$M \cdot N \cdot D_F \cdot D_F$$因此 depthwise separable convolution 的總計算量可由 depthwise 與 pointwise 兩部份相加得到
$$D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F$$將上式與傳統 CNN 的計算量進行比較,可得到下列結果
$$\frac{D_K \cdot D_K \cdot M \cdot D_F \cdot D_F + M \cdot N \cdot D_F \cdot D_F}{D_K \cdot D_k \cdot M \cdot N \cdot D_F \cdot D_F} $$ $$= \frac{1}{N} + \frac{1}{D_K^2}$$可知道原先 CNN 中的 Kernel Size 與輸出 channel 的越大,使用 depthwise separable convolution 方式所減少的計算量會更多。以一個大小 $3\times3$ 的 Kernel 來說計算量可減少到原先的 $1/8$ 到 $1/9$ 左右,對效能有非常大的幫助。以之前的 CNN 計算量範例所需的計算量為 $4,515,840$ ,而使用 Depthwise separable convolution 來計算所需的計算量為
$$3*3*1*224*224+1*10*224*244=998,144$$可看出計算成本有著非常顯著的減少了。
Experiments
Google 也在該論文中將使用了 depthwise separable convolution 方式的 MobileNet 與使用傳統 CNN 方式的模型進行比較,從結果可看出使用了使用該方式的 MobileNet 能在再稍微減低正確率的情況下,大幅改善計算效能。如下表所示:
| Model | ImageNet Accuracy | Milliion Mult-Adds | Million Parametes |
|---|---|---|---|
| Conv MobileNet | 71.7% | 4866 | 29.3 |
| MobileNet | 70.6% | 569 | 4.2 |
Conclusion
本篇文章從最基礎的 artificial neural network 的概念與架構開始介紹,並說明如何訓練 neural network,之後說明簡單的 convolutional neural network 架構與執行方式,並分析了在 convolution 計算上所需要花費的成本。之後說明 depthwise neural network 的兩層架構 - depthwise convolution 與 point wise convolution 的結構,最後比較了雙方計算架構,計算成本差異以及實驗結果比較。
Reference
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Stanford CS231n - Convolutional Neural Networks for Visual Recognition
- MobileNet - Tensorflow
- MobileNet - build with tensorflow
- TensorFlow Lite
- An Introduction to different Types of Convolutions in Deep Learning
- Google’s MobileNets on the iPhone
- Kerasの作者@fcholletさんのCVPR'17論文XceptionとGoogleのMobileNets論文を読んだ
