Autoencoder 簡介與應用範例
Autoencoder(自動編碼器)是一種是透過 Artificial Neural Network,來進行資料自動學習與編碼的技術。本文將使用機器學習函式庫 Keras 建立 Autoencoder Model,並使用 MNIST Datatset 來展示兩個 Autoencoder 範例 - 資料降維回復與**去雜訊(Denoising)**的 Model。
Autoencoder
什麼是 Autoencoder ? 簡單來說是一種透過類神經網路來自動學習資料中的特徵,以達成特定功能如 Dimension Reduction,Data Denoising 等功能的模型。
該模型主要包含三部分 - Encoding Function
$$h = f(x)$$, Decoding Function
$$r = g(h)$$與 Loss function
$$L(x, r)$$。我們希望輸入壓縮後的資料在復原後能盡可能接近原始資料,即
$$x \approx r$$。下圖為 Autoencoder 基本架構
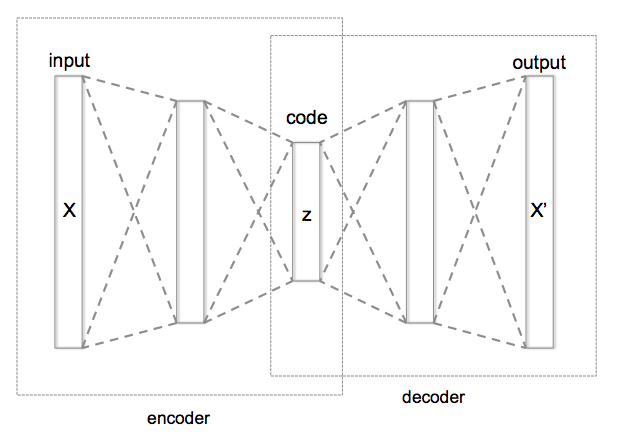
與一般的資料壓縮演算法如 Zip, MP3,JPG 等通用演算法不同,Autoencoder 有資料相依的性質。即訓練完成的 Model 只適用於特定類型資料且會損失(lossy)原始資訊。但由於 Autoencoder 不需要標示 Label 以及能自動學習的特性,可以幫助解決 Unsupervised Learning 的問題,因此仍然存在著許多發展潛力。
Regularized Autoencoders
在 Autoencoder 中,Code 的維度比輸入資料小的模型稱為 Undercomplete Autoencoder,比輸入資料大的則稱為 Overcomplete Autoencoder。上例即為 Undercomplete Autoencoder 的範例。
由於 Autoencoder 主要目的為希望能學習到資料特徵,若只是單純回復輸入得資料通常意義不大,因此比起限制 Code 維度大小,通常更傾向使 Autoencoder Model 去學習某些的特性,讓 Model 能達到特定效果。這些 Model 也被稱為 Regularized Autoencoder,如下例的 DAE(Denoising Autoencoder) 即是 Code 維度比輸入資料更大的 Model。
Examples
以下將使用 Keras 函式庫並使用 MNIST Dataset 來展示兩個 Autoencoder 範例,基本 Autoencoder 架構與 Denoising Autoencoder。該範例主要來自 Building Autoencoders in Keras 這篇文章,若需要更深入的理解可自行參考相關內容。
MNIST 資料降維與復原
MNIST 為一著名的手寫辨識資料集,在此範例中使用 Fully-Connection Neural Network,將 28 * 28 = 784 維的圖片轉換成 32 維的 Encoding Layer 後,再還原至原先的 28 * 28 維影像資料並比較雙方差異。
# 讀取 MNIST dataset 並進行前處理
from keras.datasets import mnist
import numpy as np
# x_train: Autoencoder 訓練資料
# x_test: Autoencoder 測試資料
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255. # 正規化資料數值範圍至 [0, 1] 間
x_test = x_test.astype('float32') / 255.
# 正規化資料維度,以便 Keras 處理
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
資料讀取完成後,接著建立 Autoencoder Model 並使用 x_train 資料進行訓練。
from keras.layers import Input, Dense
from keras.models import Model
input_img = Input(shape=(784,))
encoded = Dense(32, activation='relu')(input_img) ## Encoding layer 設為 32 維
decoded = Dense(784, activation='sigmoid')(encoded) ## Decoding layer 設為與 input layer 相同的 784 維
# 建立 Model 並將 loss funciton 設為 binary cross entropy
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train,
x_train, # Label 也設為 x_train
epochs=25,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test))
訓練完後可以得到 loss 值約為 0.1049 以及 Validation loss 為 0.1029 的 Autoencoder Model。下圖為將 x_test 資料輸入 autoencoder 物件後的得到的結果圖片。
 (Top) 原始影像。 (Middle) 32維編碼資料以 8*4 平面呈現。 (Bottom) 輸出結果。
(Top) 原始影像。 (Middle) 32維編碼資料以 8*4 平面呈現。 (Bottom) 輸出結果。
從上圖可看出,即使將原先 28*28 = 784 維的資料轉換到 32 維的資料後再復原回原先的圖片,仍能保留相關特徵存在。
Denosing Autoencoder (DAE)
最初的 Autoencoder 為使用相同的輸入與輸出來建立 Model,但我們也可以對 Model 做一些修改來達成其他效果。如對輸入的資料
$$x$$加入的 noise 使
$$\tilde{x}=noise(x)$$。現在使用
$$\tilde{x}$$做為訓練資料而
$$x$$為輸出結果進行訓練。即讓 Loss function 為
$$L(x, g( f( \tilde{x} )))$$可得到一個對原始資料具有去雜訊功能的 Model。
noise_factor = 0.5 # 決定 noise 的數量,值越大 noise 越多
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
# 將資料限制在 [0, 1] 之間的範圍內
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
使用加入 Noise 的資料建立 Autoencoder Model 並進行訓練
input_img = Input(shape=(28, 28, 1))
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
# encoded size = (7, 7, 32) dimension
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
# Decoded size = (28, 28, 1) dimension (Original size)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 訓練 DAE Model
autoencoder.fit(x_train_noisy, # 加入 noise 的資料為輸入
x_train, # 原始資料為 Label
epochs=20,
batch_size=256,
shuffle=True,
validation_data=(x_test_noisy, x_test))
訓練後可得到一個 Denoising Autoencoder Model。現建立加入不同雜訊數量的 MNIST 影像資料輸入訓練完成的 DAE 中得到的 denoising 的結果。
 Source Image
Source Image
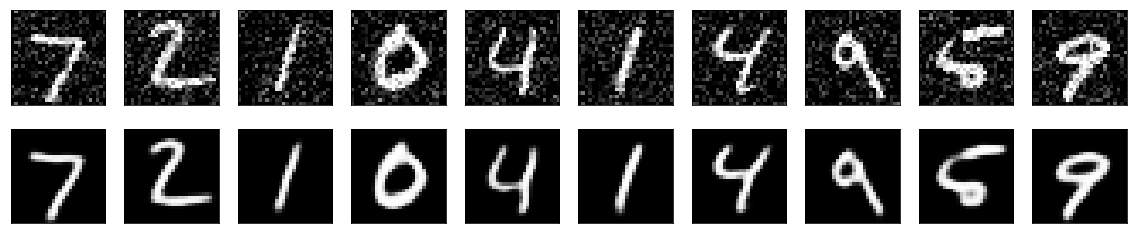 Noise = 0.2
Noise = 0.2
 Noise = 0.5
Noise = 0.5
 Noise = 0.8
Noise = 0.8
可以看出訓練之後的模型,對不同程度的雜訊都有一定的抗噪作用,能回覆原先大部分的結構。即使是使用 Noise = 0.5 的資料加以訓練,也能一定程度還原 Noise = 0.8 的資料內容。
