Generative Adversarial Networks Tutorial
Generative Adversarial Networks(生成式對抗網路,以下簡稱GANs)是近年來備受矚目的機器學習框架。 自從Ian Goodfellow於2014年提出GANs的概念後, 許多研究人員與企業如Google,Facebook與Apple等代表性公司均相繼投入了GANs的應用研究與發展, 並產生了許多衍生模型。 Machine Learning界大師Yann LeCun也稱GANs為近十年來最有趣的想法。 此篇文章將簡單介紹Ian Goodfellow所提出的最原始GANs概念,以及其之後的衍生應用。
Basic
介紹GANs之前,先簡單介紹兩個Machine Learning中的重要模型類別, Generative Model(生成模型)與 Discriminative Model(判別模型)。
-
Generative Model:可看成是一種機率分佈模型,可從訓練資料中找出最符合資料分布的模型參數,如 Hidden Markov Model與 Gaussian Mixture Model等。
-
Discriminative Model:透過訓練資料,使模型學習如何去判定資料的類別,如 Neural Network, Logistical Regression等。
一個比喻是,模型透過學習貓的外表後,Discriminative Model則可以判別資料是否是屬於貓的類別,而Generative Model可以畫出一隻貓來。
GANs
GANs為一種Generative Model,但與之前的架構不同的是,GANs在訓練過程中加入了另一個Discriminative Model,透過Model間的相互對抗(Adversarial)的過程加強兩者,已達到更好的效果。如果以人類的角度來說,可以想像成名畫鑑定者與偽造者之間的互相對抗的過程。鑑定者透過原作者的作品,以及偽造者產生的假名畫,加強自身的鑑別能力。而偽造者不斷加強自身的偽造能力來欺騙鑑定者,在一來一往的過程中,偽造者與鑑定者都不斷加強自身的能力,直到偽造者能產生與原始名畫不相上下的作品為止。
Framework
在GANs的架構中,我們可以定義以下的角色
- $$G$$:Generative Model,擔任偽造者角色,將產生的輸出導入$$D$$中做判別。
- $$D$$:Discriminative Model,擔任鑑定者的角色,對輸入的資料進行判斷。
- $$X$$:訓練資料集,輸入$$D$$ 中進行訓練。
- $$Z$$:隨機雜訊(Random Noise),為$$G$$的輸入值。
之後依照以下步驟訓練GANs
- 對$$G$$與$$D$$兩個Model,配合訓練資料集與隨機雜訊資料一起訓練,加強$$D$$的分辨能力。
- 使用Random noise對$$G$$進行獨立訓練,加強$$G$$的偽造能力。
- 重複1,2的步驟直到訓練結束。
訓練結束後我們可以得到一個輸入資料後,即可輸出特定產出的Generative Model
$$G$$。基礎架構圖如下所示
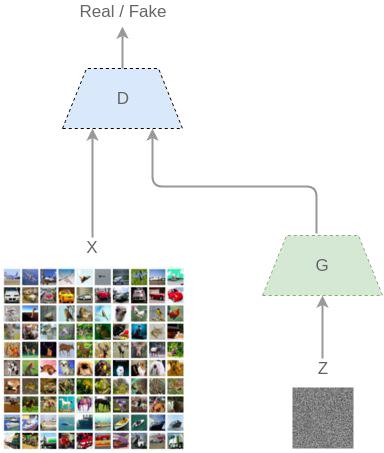
Ian Goodfellow在原始論文中給出了使用MNIST與TFD(Toronto Face DataSet)資料集的實驗結果。


圖片中最右邊的黃框為訓練資料中最接近結果的產出,其他為Generative Model的輸出結果,從圖片中可看出透過GANs訓練出來的Generative Model,可產生接近原始訓練資料集的輸出。
Advance
由於GANs展現出來的新架構與發展潛力,許多對GANs的研究與改進在近幾年也紛紛出籠,其中之一為被稱做Conditional GANs的概念。想法是將另外的資訊加入GANs訓練中,使Generative Model的輸出偏向特定的結果。如下面的兩項研究:
將文字描述加入圖片進行訓練,之後得到的模型可依照輸入的文字,輸出偏向特定結果的輸出。下圖顯示,當輸入文字為Bird時,會產生的圖片會有接近Bird(鳥)內容。而加入White Flower(白花)的條件時,則會產生帶有接近白色花朵的圖片。

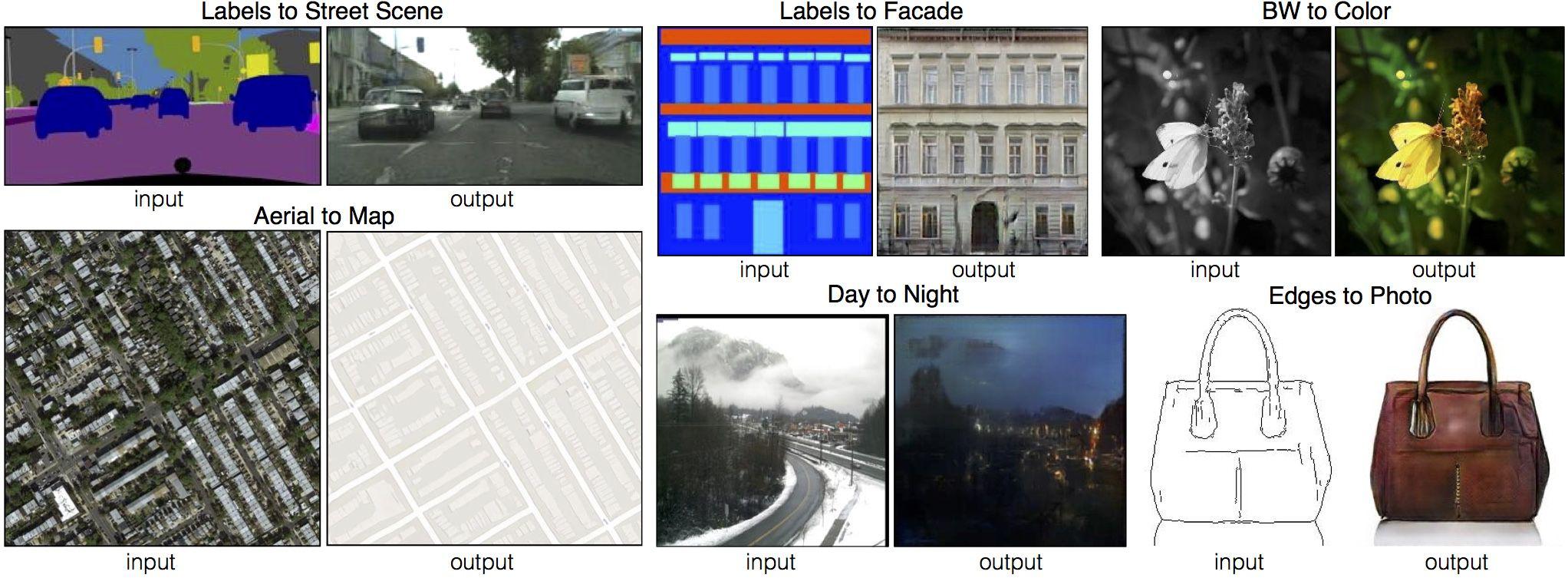
將原始圖片與該圖片的圖像分割資料來進行訓練,之後將分割資料給輸入Model即可產生出對應分割資料的新圖片。如下圖右下,將皮包邊緣影像輸入模型,可畫出一個近似皮包的物體圖片。
此外也有許多對於原始GANs理論的改進,如被稱為Wasserstein GAN的模型,以及對其進一步的改善研究等,都可以看出GANs架構在今後的巨大發展潛力。
